Diffusion Models 이란
Diffusion Models 이란?
diffusion-models 이글을 번역한 내용 입니다
지금까지 세 가지 유형의 생성 모델, 즉 GAN, VAE 및 흐름 기반(FLOW-based) 모델에 대해 작성했습니다. 이 모델들은 고품질 샘플을 생성하는 데 큰 성공을 거두었지만 각각 몇 가지 한계가 있습니다. GAN 모델은 적대적 훈련 특성으로 인해 잠재적으로 불안정한 훈련과 생성의 다양성이 떨어지는 것으로 알려져 있습니다. VAE는 대리 손실에 의존합니다. FLOW 모델은 가역적 변환을 구축하기 위해 특수 아키텍처를 사용해야 합니다.
확산 모델(Diffusion models)은 비평형 열역학(non-equilibrium thermodynamics)에서 영감을 얻었습니다. 확산 단계의 마르코프 체인(Markov chain)을 정의하여 데이터에 무작위 노이즈를 천천히 추가한 다음, 확산 과정을 역으로 학습하여 노이즈에서 원하는 데이터 샘플을 구성하는 방법을 학습합니다. 확산 모델은 VAE 또는 흐름 모델과 달리 고정된 절차로 학습되며 잠재 변수는 높은 차원(원본 데이터와 동일)을 갖습니다.

확산 모델이란?
Several diffusion-based generative models have been proposed with similar ideas underneath, including diffusion probabilistic models (Sohl-Dickstein et al., 2015), noise-conditioned score network (NCSN; Yang & Ermon, 2019), and denoising diffusion probabilistic models (DDPM; Ho et al. 2020).
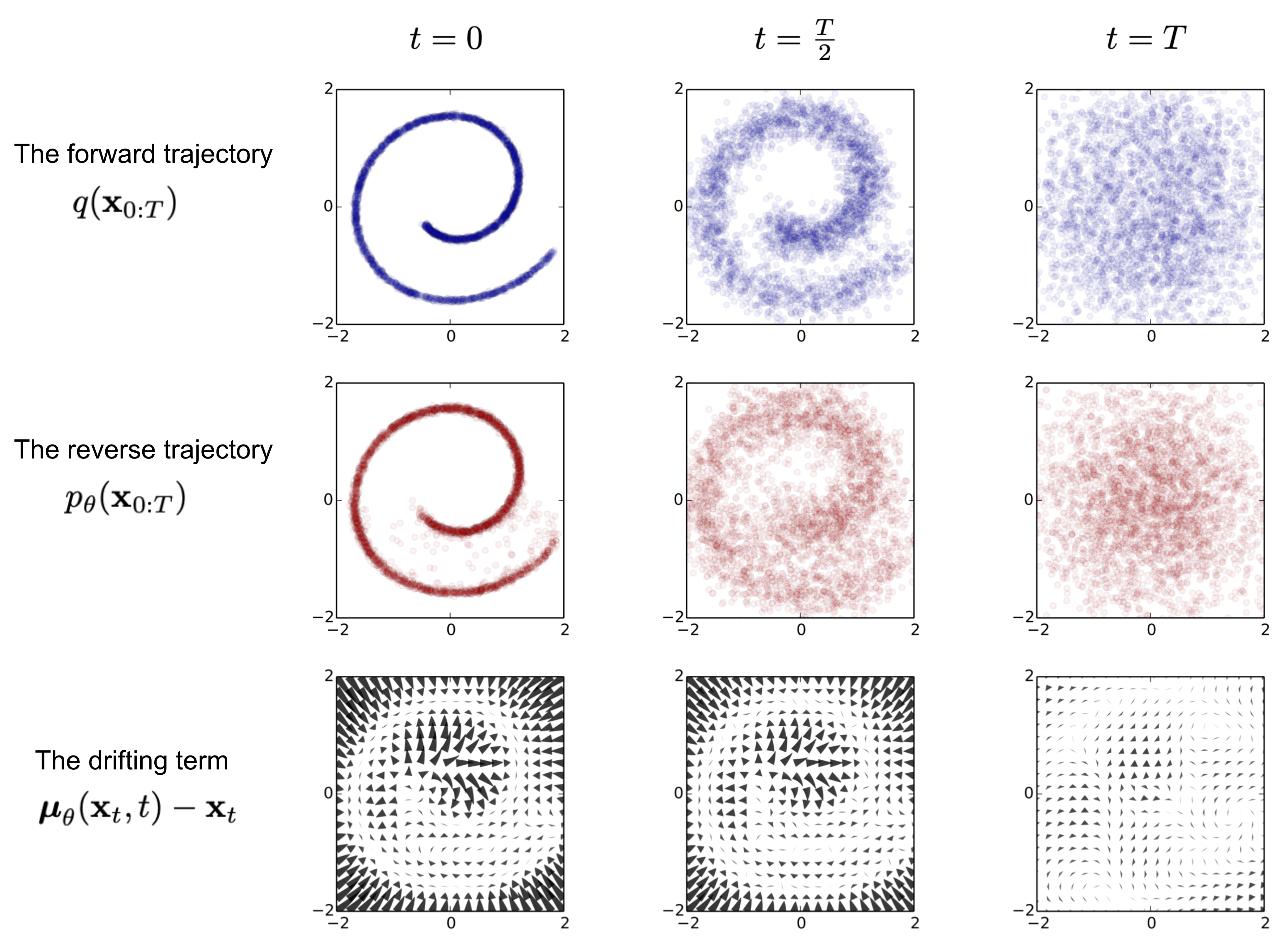
순방향 확산 프로세스 (Forward diffusion process)
실제 데이터 분포에서 샘플링된 데이터 포인트가 주어지면 샘플에 소량의 가우시안(Gaussian) 노이즈를 추가하는 순방향 확산 프로세스를 정의해 보겠습니다. T 단계, 시끄러운 샘플 시퀀스 생성 x...x 단계 크기는 분산 일정에 의해 제어됩니다. 데이터 샘플 점차적으로 단계적으로 구별되는 특징을 잃습니다. 더 커집니다. 결국 언제 등방성 가우스 분포와 동일합니다.
확률적 경사 Langevin 역학과의 연결
Langevin 역학은 분자 시스템을 통계적으로 모델링하기 위해 개발된 물리학의 개념입니다. 확률적 경사하강법과 결합된 Stochastic Gradient Langevin 역학 Bayesian Learning via Stochastic Gradient Langevin Dynamics 은 확률 밀도에서 샘플을 생성할 수 있습니다.
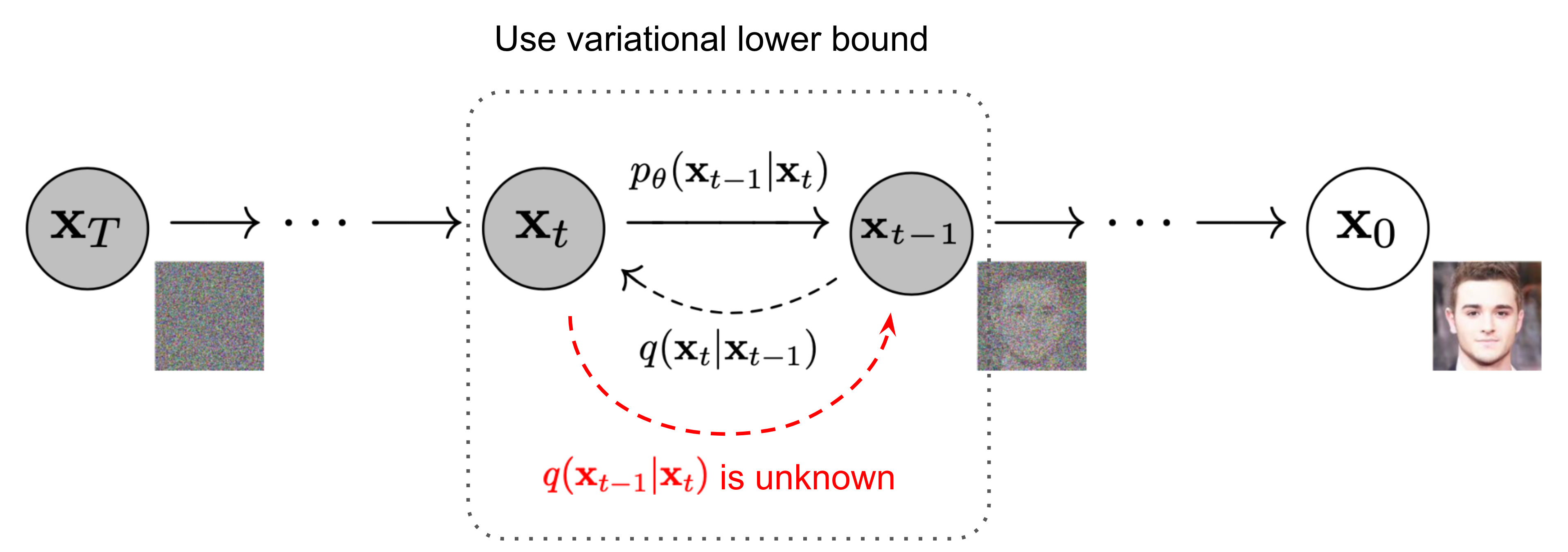
역확산 과정(Reverse diffusion process)
위의 과정을 반대로 하고 샘플을 추출할 수 있다면 가우스 노이즈 입력에서 실제 샘플을 다시 생성할 수 있습니다. 안타깝게도 쉽게 추정할 수는 없습니다. 전체 데이터 세트를 사용해야 하므로 모델을 학습해야 하기 때문입니다. 역확산 프로세스를 실행하기 위해 이러한 조건부 확률을 근사화합니다 .
확산 모델 샘플링 속도 향상
역확산 과정의 마르코프 체인을 따라 DDPM에서 샘플을 생성하는 것은 다음과 같이 매우 느립니다. 최대 1단계 또는 수천 단계일 수 있습니다. Song et al. 의 한 데이터 포인트 . 2020 : "예를 들어 DDPM에서 32 × 32 크기의 이미지 50,000개를 샘플링하는 데 약 20시간이 걸리지만 Nvidia 2080 Ti GPU의 GAN에서는 1분도 채 걸리지 않습니다."
간단한 방법 중 하나는 샘플링 업데이트를 매번 수행하여 점진적인 샘플링 일정( Nichol & Dhariwal, 2021 )을 실행하는 것입니다.
DDPM과 비교하여 DDIM은 다음을 수행할 수 있습니다.
- 훨씬 적은 수의 단계를 사용하여 고품질 샘플을 생성합니다.
- 생성 프로세스는 결정론적이므로 "일관성" 속성을 갖습니다. 즉, 동일한 잠재 변수에 대해 조건화된 여러 샘플이 유사한 상위 수준 특징을 가져야 함을 의미합니다.
- 일관성으로 인해 DDIM은 잠재 변수에서 의미상 의미 있는 보간을 수행할 수 있습니다.
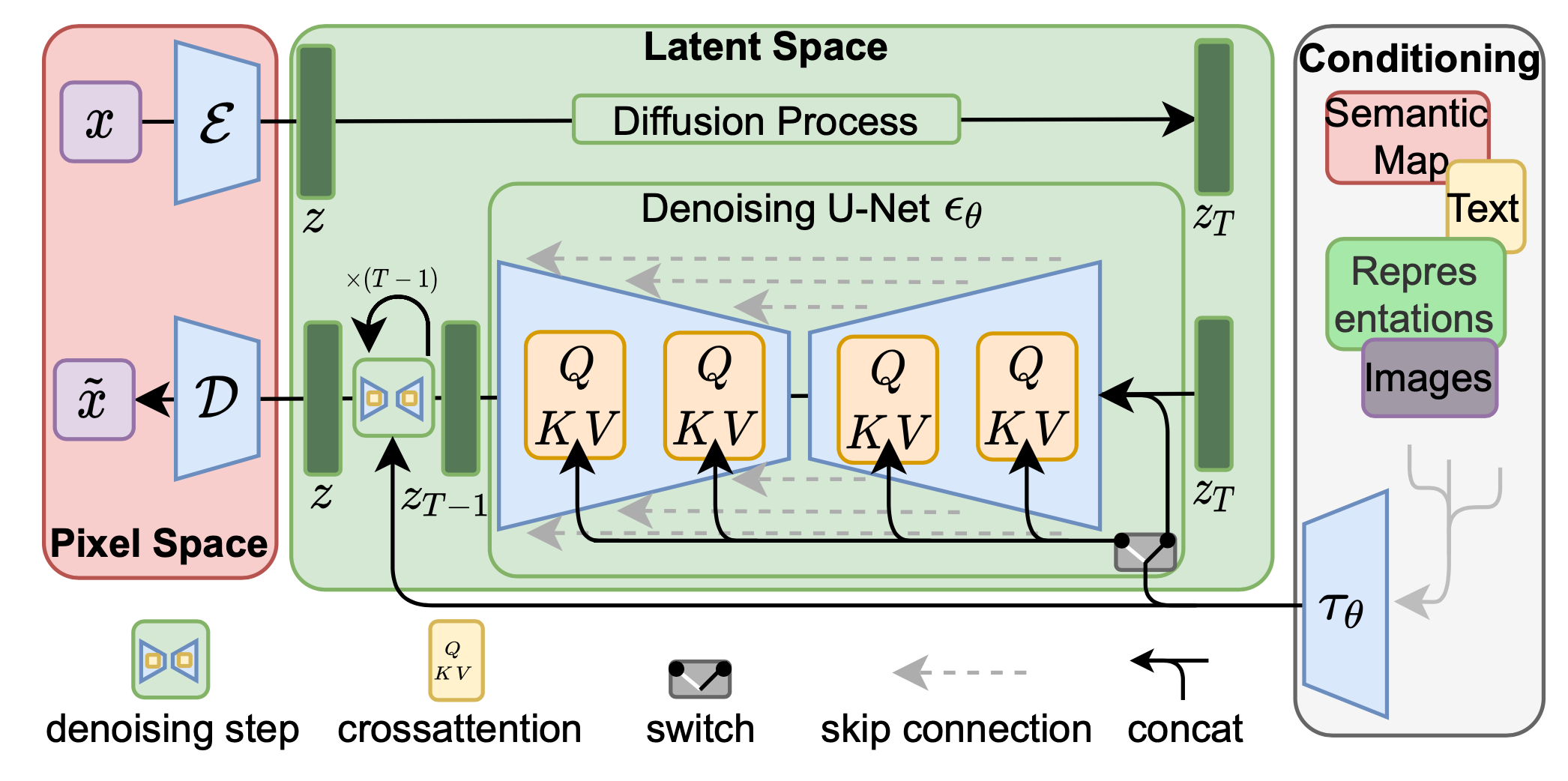
잠재 확산 모델(LDM ; Rombach & Blattmann, et al. 2022 )은 픽셀 공간 대신 잠재 공간에서 확산 프로세스를 실행하므로 훈련 비용이 낮아지고 추론 속도가 빨라집니다. 이미지의 대부분의 비트가 지각적 세부 사항에 기여하고 공격적인 압축 후에도 의미론적 및 개념적 구성이 여전히 남아 있다는 관찰에 의해 동기가 부여되었습니다. LDM은 먼저 자동 인코더로 픽셀 수준 중복성을 제거한 다음 학습된 잠재성에 대한 확산 프로세스를 통해 의미론적 개념을 조작/생성하여 생성 모델링 학습을 통해 지각 압축과 의미론적 압축을 느슨하게 분해합니다.
지각적 압축 프로세스는 오토인코더 모델에 의존합니다. 인코더 입력 이미지를 압축하는 데 사용됩니다. 더 작은 2D 잠재 벡터로 여기서 다운샘플링 속도는. 그런 다음 디코더 잠재 벡터로부터 이미지를 재구성합니다. 이 논문에서는 잠재 공간에서 임의로 높은 분산을 방지하기 위해 오토인코더 훈련에서 두 가지 유형의 정규화를 탐구했습니다.
- KL-reg: 학습된 잠재성에 대한 표준 정규 분포에 대한 작은 KL 페널티로, VAE 와 유사합니다 .
- VQ-reg: VQVAE 와 같이 디코더 내에서 벡터 양자화 계층을 사용 하지만 양자화 계층은 디코더에 의해 흡수됩니다.
확산 및 노이즈 제거 프로세스는 잠재 벡터에서 발생합니다. 잡음 제거 모델은 이미지 생성을 위한 유연한 조건화 정보(예: 클래스 레이블, 의미 지도, 이미지의 흐릿한 변형)를 처리하기 위해 교차 주의 메커니즘이 강화된 시간 조건화된 U-Net입니다. 이 디자인은 교차 주의 메커니즘을 사용하여 다양한 양식의 표현을 모델에 융합하는 것과 동일합니다. 각 유형의 조건화 정보는 도메인별 인코더와 쌍을 이룹니다. 조건 입력을 투영하기 위해 교차 주의 구성 요소에 매핑될 수 있는 중간 표현으로,
Conditioned Generation
ImageNet 데이터세트와 같은 조건부 정보가 있는 이미지에 대해 생성 모델을 훈련하는 동안 클래스 레이블이나 설명 텍스트를 기준으로 조건부 샘플을 생성하는 것이 일반적입니다.
Classifier Guided Diffusion
클래스 정보를 확산 프로세스에 명시적으로 통합하기 위해 Dhariwal & Nichol(2021)은 분류기를 교육했습니다. 시끄러운 이미지에 그리고 그라디언트를 사용하세요 컨디셔닝 정보에 대한 확산 샘플링 프로세스를 안내합니다. (예: 대상 클래스 레이블) 노이즈 예측을 변경합니다. 그것을 기억해 공동 분포에 대한 점수 함수를 작성할 수 있습니다. 다음과 같이,
따라서 새로운 분류기 안내 예측기는 다음과 같은 형식을 취합니다.
분류자 지침의 강도를 제어하기 위해 가중치를 추가할 수 있습니다.
결과적으로 제거된 확산 모델 ( ADM )과 추가 분류자 지침이 있는 모델( ADM-G )은 SOTA 생성 모델(예: BigGAN)보다 더 나은 결과를 얻을 수 있습니다.
또한 U-Net 아키텍처를 일부 수정하여 Diffusion Models Beat GANs on Image Synthesis은 확산 모델을 사용하는 GAN보다 더 나은 성능을 보여주었습니다. 아키텍처 수정에는 더 큰 모델 깊이/너비, 더 많은 주의 헤드, 다중 해상도 주의, 업/다운샘플링을 위한 BigGAN 잔여 블록, 잔여 연결 재조정이 포함됩니다.
Classifier-Free Guidance
독립적인 분류기가 없는 경우 , 조건부 확산 모델과 무조건 확산 모델의 점수를 통합하여 조건부 확산 단계를 실행하는 것이 여전히 가능합니다( Ho & Salimans, 2021 ). 무조건적 노이즈 제거 확산 모델을 보자 점수 추정기를 통해 매개변수화됨 그리고 조건부 모델 매개변수화를 통해. 이 두 모델은 단일 신경망을 통해 학습할 수 있습니다. 정확히 말하면 조건부 확산 모델 쌍을 이루는 데이터에 대해 학습됩니다. 여기서 조건화 정보는 모델이 무조건 이미지를 생성하는 방법을 알 수 있도록 주기적으로 무작위로 삭제됩니다.
암시적 분류기의 기울기는 조건부 및 무조건 점수 추정기로 표현될 수 있습니다. 분류자가 안내하는 수정된 점수에 연결되면 점수는 별도의 분류자에 대한 종속성을 포함하지 않습니다.
그들의 실험에서는 분류기가 없는 지침이 FID(합성 이미지와 생성된 이미지 구별)와 IS(품질과 다양성) 사이에서 좋은 균형을 이룰 수 있음을 보여주었습니다.
안내 확산 모델인 GLIDE( Nichol, Dhariwal & Ramesh, et al. 2022 )는 안내 전략, CLIP 안내 및 분류자 없는 안내를 모두 탐색한 결과 후자가 더 선호되는 것으로 나타났습니다. 그들은 CLIP 지침이 더 잘 일치하는 이미지 생성을 최적화하는 대신 CLIP 모델에 대한 적대적인 예를 사용하여 모델을 활용하기 때문이라고 가정했습니다.
Scale up Generation Resolution and Quality
고해상도에서 고품질 이미지를 생성하기 위해 Ho et al. (2021)은 증가하는 해상도에서 다중 확산 모델의 파이프라인을 사용할 것을 제안했습니다. 파이프라인 모델 간의 노이즈 조절 증대는 최종 이미지 품질에 매우 중요하며, 이는 조절 입력에 강력한 데이터 증대를 적용하는 것입니다.
각 초해상도 모델의 컨디셔닝 노이즈는 파이프라인 설정의 복합 오류를 줄이는 데 도움이 됩니다. U-net은 고해상도 이미지 생성을 위한 확산 모델링에서 일반적인 모델 아키텍처 선택입니다.
![그림 11. 증가하는 해상도에서 다중 확산 모델의 계단식 파이프라인. (이미지 출처: Ho et al. 2021 ])](https://lilianweng.github.io/posts/2021-07-11-diffusion-models/cascaded-diffusion.png)
그들은 가장 효과적인 노이즈가 낮은 해상도에서 가우스 노이즈를 적용하고 고해상도에서 가우시안 블러를 적용하는 것임을 발견했습니다. 또한 그들은 훈련 과정에 약간의 수정이 필요한 두 가지 형태의 컨디셔닝 강화도 탐구했습니다. 컨디셔닝 노이즈는 훈련에만 적용되고 추론에는 적용되지 않습니다.
- Truncated Conditioning Augment는 단계 초기에 확산 프로세스를 중지합니다. 저해상도용.
- 잘리지 않은 조건화 확대는 0단계까지 전체 저해상도 역 프로세스를 실행하지만 다음과 같이 손상됩니다.
- 그런 다음 부패한 동물에게 먹이를 줍니다. 초해상도 모델에 들어갑니다.
2단계 확산 모델 unCLIP ( Ramesh et al. 2022 )은 CLIP 텍스트 인코더를 많이 활용하여 고품질의 텍스트 안내 이미지를 생성합니다. 사전 훈련된 CLIP 모델이 주어지면 확산 모델에 대한 쌍을 이루는 훈련 데이터,, 어디 이미지이고 해당 캡션을 사용하면 CLIP 텍스트 및 이미지 임베딩을 계산할 수 있습니다. 그리고, 각각. unCLIP은 두 가지 모델을 병렬로 학습합니다.
- 이전 모델 :CLIP 이미지 임베딩을 출력합니다. 주어진 텍스트
- 디코더 : 이미지를 생성합니다 주어진 CLIP 이미지 임베딩 선택적으로 원본 텍스트 . 이 두 모델은 조건부 생성을 가능하게 합니다.
unCLIP은 2단계 이미지 생성 프로세스를 따릅니다.
- 텍스트가 주어짐 CLIP 모델은 먼저 텍스트 임베딩을 생성하는 데 사용됩니다. CLIP 잠재 공간을 사용하면 텍스트를 통해 제로샷 이미지 조작이 가능해집니다.
- 확산 또는 자기회귀 사전 이 CLIP 텍스트 임베딩을 처리하여 이미지를 먼저 구성한 다음 확산 디코더를 구성합니다. 사전 조건에 따라 이미지를 생성합니다. 이 디코더는 이미지 입력에 따라 이미지 변형을 생성하여 스타일과 의미를 보존할 수도 있습니다.
CLIP 모델 대신 Imagen ( Saharia et al. 2022 )은 사전 훈련된 대형 LM(즉, 고정된 T5-XXL 텍스트 인코더)을 사용하여 이미지 생성을 위한 텍스트를 인코딩합니다. 모델 크기가 클수록 이미지 품질이 향상되고 텍스트-이미지 정렬이 향상되는 일반적인 경향이 있습니다. 그들은 T5-XXL과 CLIP 텍스트 인코더가 MS-COCO에서 유사한 성능을 달성하지만 인간 평가에서는 DrawBench(11개 범주를 다루는 프롬프트 모음)에서 T5-XXL을 선호한다는 것을 발견했습니다.
분류자 없는 지침을 적용하면 증가합니다. 이미지-텍스트 정렬은 향상되지만 이미지 충실도는 저하될 수 있습니다. 그들은 훈련-테스트 불일치, 즉 훈련 데이터 때문에 발생한다는 것을 발견했습니다. 범위 내에서 유지됩니다., 테스트 데이터도 그래야 합니다. 두 가지 임계값 전략이 도입되었습니다
- 정적 임계값: 클립 에 대한 예측
- 동적 임계값: 각 샘플링 단계에서 다음을 계산합니다. 특정 백분위수 절대 픽셀 값으로; 만약에 예측을 다음으로 자릅니다. 그리고 다음으로 나눈다
Imagen은 U- net을 효율적으로 만들기 위해 U-net의 여러 디자인을 수정합니다 .
- 낮은 해상도에 더 많은 잔여 잠금(residual locks)을 추가하여 모델 매개변수를 고해상도 블록에서 저해상도로 전환합니다.
- 건너뛰기 연결 크기 조정
- 순방향 전달 속도를 향상시키기 위해 다운샘플링(컨볼루션 전에 이동) 및 업샘플링 작업(컨볼루션 후 이동)의 순서를 반대로 바꿉니다.
그들은 잡음 조절 증대, 동적 임계값 지정 및 효율적인 U-Net이 이미지 품질에 중요하지만 텍스트 인코더 크기 조정이 U-Net 크기보다 더 중요하다는 것을 발견했습니다.
빠른 요약
-
장점 : 다루기 쉽고 유연성은 생성 모델링에서 두 가지 상충되는 목표입니다. 다루기 쉬운 모델은 분석적으로 평가하고 데이터를 저렴하게 맞출 수 있지만(예: Gaussian 또는 Laplace를 통해) 풍부한 데이터세트의 구조를 쉽게 설명할 수는 없습니다. 유연한 모델은 데이터의 임의 구조에 적합할 수 있지만 이러한 모델의 평가, 훈련 또는 샘플링에는 일반적으로 비용이 많이 듭니다. 확산 모델은 분석적으로 다루기 쉽고 유연합니다.
-
단점 : 확산 모델은 샘플을 생성하기 위해 긴 Markov 확산 단계 체인을 사용하므로 시간과 계산 측면에서 상당히 비쌀 수 있습니다. 프로세스를 훨씬 빠르게 만들기 위해 새로운 방법이 제안되었지만 샘플링은 여전히 GAN보다 느립니다.
참조
- diffusion-models
- 마르코프 연쇄
- 마르코프 체인에 관하여
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics
- Generative Modeling by Estimating Gradients of the Data Distribution
- Denoising Diffusion Probabilistic Models
- Reparameterization Trick
- Bayesian Learning via Stochastic Gradient Langevin Dynamics
- Diffusion Models Beat GANs on Image Synthesis
- Diffusion model 설명 (Diffusion model이란? Diffusion model 증명)
- Diffusion Model 설명 – 기초부터 응용까지