
Memory Management in the Java HotSpot™ Virtual Machine(Sun Microsystems April 2006)
1 Introduction
Java ™ 2 Platform, Standard Edition (J2SE ™)의 장점 중 하나는 자동 메모리를 수행한다는 것입니다
이로써 개발자는 명시 적 메모리 관리의 복잡성으로부터 개발자를 보호합니다.
이 백서에서는 Java HotSpot 가상 시스템 (JVM)의 메모리 관리에 대한 전반적인 개요를 제공합니다.
Sun의 J2SE 5.0 릴리스. 메모리 관리를 수행 할 수있는 가비지 콜렉터에 대해 설명하고,
수집기 선택 및 구성 및 메모리 영역의 크기 설정에 대한 조언을 제공합니다.
수집기가 작동합니다. 또한 리소스로도 사용되며 가장 일반적으로 사용되는 옵션 중 일부를 나열합니다.
가비지 컬렉터 동작에 영향을 주며보다 자세한 문서에 대한 수많은 링크를 제공합니다.
섹션 2는 자동 메모리 관리 개념을 처음 접하는 독자를위한 것입니다. 간단한 토론이있다.
프로그래머가 데이터 공간을 명시 적으로 할당 해제하도록 요구하는 대신 이러한 관리의 이점을 누릴 수 있습니다.
3 장에서는 일반 가비지 콜렉션 개념, 설계 선택 및 성능에 대한 개요를 제시합니다.
측정 항목 또한 일반적으로 사용되는 메모리 조직을 세대라고하는 여러 영역에 도입합니다.
개체의 예상 수명을 기준으로합니다. 세대로의이 분리는 감소시키는 데 효과적이라는 것이 입증되었습니다.
가비지 수집 일시 중지 시간 및 광범위한 응용 프로그램에서의 전반적인 비용.
이 문서의 나머지 부분에서는 HotSpot JVM 관련 정보를 제공합니다. 섹션 4에서는 네 가지 쓰레기
사용 가능한 수집기 (J2SE 5.0 업데이트 6의 새로운 기능 포함) 및 생성기
그들 모두가 활용하는 기억 조직. 각 수집기에 대해 섹션 4는 수집 알고리즘의 유형을 요약합니다
사용되며 해당 수집기를 선택하는 것이 적절한시기를 지정합니다.
5 절에서는 J2SE 5.0 릴리스의 새로운 기술에 대해 설명합니다.이 기술은 (1) 쓰레기 자동 선택
콜렉터, 힙 크기 및 HotSpot JVM (클라이언트 또는 서버)을 기반으로하는 플랫폼 및 운영 체제
응용 프로그램이 실행 중이고, (2) 사용자 지정 원하는 동작을 기반으로하는 동적 가비지 수집 조정.
이 기술을 인간 공학이라고합니다.
6 절에서는 가비지 수집기 선택 및 구성에 대한 권장 사항을 제공합니다. 또한
OutOfMemoryErrors에 대해 할 일에 대한 조언. 섹션 7에서는 몇 가지 도구를 간략하게 설명합니다.
가비지 수집 성능을 평가하는 데 사용되며 섹션 8에서는 가장 일반적으로 사용되는 명령 줄
가비지 수집기 선택 및 동작과 관련된 옵션 마지막으로 섹션 9에서는보다 자세한
이 문서에서 다루는 다양한 주제에 대한 문서
2 Explicit vs. Automatic Memory Management
메모리 관리는 할당 된 객체가 더 이상 필요하지 않을 때를 인식하고 할당을 해제하는 프로세스입니다.
그러한 객체가 사용하는 메모리를 비우는 (freeing) 것. 일부
프로그래밍 언어, 메모리 관리는 프로그래머의 책임입니다. 그 업무의 복잡성
예기치 않은 또는 잘못된 프로그램 동작 및 충돌을 일으킬 수있는 많은 일반적인 오류가 발생합니다. 마찬가지로
결과적으로 개발자 시간의 대부분은 종종 디버깅에 소요되며 이러한 오류를 수정하려고합니다.
명시 적 메모리 관리가있는 프로그램에서 종종 발생하는 한 가지 문제는 참조가 매달려 있다는 것입니다. 그것은
다른 객체가 여전히 참조를 가지고있는 객체가 사용하는 공간을 할당 해제 할 수 있습니다. 오브젝트
(댕글 링) 참조가 원래 객체에 액세스하려고 시도하지만 공간이 새로운 객체로 재 할당되었습니다.
결과는 예측할 수 없으며 의도 한 것이 아닙니다.
명시 적 메모리 관리와 관련된 또 다른 공통적 인 문제점은 공간 누수입니다. 이러한 누출은 메모리가
할당되고 더 이상 참조되지는 않지만 해제되지는 않습니다. 예를 들어, 귀하가 사용하는 공간을 확보하려는 경우
링크 된 목록하지만 목록의 첫 번째 요소를 할당 취소 실수로, 나머지 목록 요소
더 이상 참조되지는 않지만 프로그램의 범위를 벗어나 사용 및 복구 할 수 없습니다. 만약
충분한 누수가 발생하면 사용 가능한 모든 메모리가 모두 소모 될 때까지 메모리를 계속 사용할 수 있습니다.
특히 현재 가장 보편적으로 사용되는 메모리 관리에 대한 대체 접근 방식
객체 지향 언어는 가비지 수집기라는 프로그램에 의한 자동 관리입니다. 오토매틱
메모리 관리는 인터페이스의 추상화 및보다 안정적인 코드를 가능하게합니다.
가비지 콜렉션은 매달려있는 참조 문제를 피합니다. 여전히 어딘가에서 참조 된 객체
쓰레기 수거되지 않으므로 무료로 간주되지 않습니다. 가비지 수집으로 공간 누출 문제 해결
위에서 언급 한 문제는 더 이상 참조되지 않은 모든 메모리를 자동으로 해제하기 때문입니다.
3 Garbage Collection Concepts
가비지 컬렉터는
- 메모리 할당
- 참조 된 객체가 메모리에 남아 있는지 확인하고, 코드 실행시 참조에서 더 이상 접근 할 수없는 객체가 사용하는 메모리를 복구합니다.
참조 된 오브젝트는 라이브라고합니다. 더 이상 참조되지 않는 객체는 죽은 것으로 간주되며
쓰레기. 이러한 개체가 사용하는 공간을 찾아서 해제하는 작업 (교정이라고도 함)
쓰레기 수거라고합니다.
가비지 수집은 많은 메모리 할당 문제를 해결하지만 전부는 아닙니다. 예를 들어, 객체를 생성 할 수 있습니다.
무기한 사용할 수있는 메모리가 없어 질 때까지 계속 참조하십시오. 가비지 수집 또한
복잡한 작업은 자체 시간과 자원을 필요로합니다.
메모리를 구성하고 공간을 할당하고 할당을 해제하는 데 사용되는 정확한 알고리즘은 쓰레기로 처리됩니다.
콜렉터이며 프로그래머에게 숨겨져 있습니다. 공간은 일반적으로 참조 된 많은 메모리 풀에서 할당됩니다.
힙으로.
가비지 콜렉션의 타이밍은 가비지 콜렉터에 달려 있습니다. 일반적으로 전체 힙 또는 하위 부분은 다음과 같습니다.
그것이 채워지거나 점유의 임계 비율에 도달 할 때 수집됩니다.
특정 크기의 사용되지 않은 메모리 블록을 찾기 위해 할당 요청을 수행하는 작업
힙은 어려운 것입니다. 대부분의 동적 메모리 할당 알고리즘의 주요 문제점은
(아래 참조), 할당과 할당 해제를 모두 효율적으로 유지합니다.
Desirable Garbage Collector Characteristics
가비지 수집기는 안전하고 포괄적이어야합니다. 즉, 라이브 데이터를 잘못해서는 안됩니다.
소량의 수거주기 이상을 위해 쓰레기를 버리지 말아야합니다.
가비지 컬렉터가 긴 정지를 도입하지 않고 효율적으로 작동하는 것이 바람직합니다.
응용 프로그램이 실행되고 있지 않습니다. 그러나 대부분의 컴퓨터 관련 시스템과 마찬가지로 종종 다음과 같은 절충안이 있습니다.
시간, 공간 및 빈도. 예를 들어, 힙 크기가 작 으면 모음은 빠르지 만 힙이 채워집니다
보다 신속하게 수집 할 수 있으므로 더 자주 수집해야합니다. 반대로 대량의 힙은 채우기까지 더 오래 걸리고
따라서 수집 빈도는 적지 만 오랜 시간이 걸릴 수 있습니다.
또 다른 바람직한 가비지 콜렉터 특성은 단편화의 한계입니다. 메모리가
가비지 개체가 해제되면 여유 공간이 여러 영역의 작은 덩어리로 나타날 수 있으므로
큰 물체의 할당을 위해 사용되는 하나의 인접한 영역에 충분한 공간이 있어야합니다. 한 가지 접근법
단편화를 제거하는 것을 압축이라고하며, 다양한 가비지 컬렉터 디자인 중에서 논의됩니다.
이하.
확장 성 또한 중요합니다. 다중 스레드의 경우 확장 성 병목 현상이 발생해서는 안됩니다.
다중 프로세서 시스템의 응용 프로그램 및 콜렉션도 병목 현상이 발생하지 않아야합니다.
Design Choices
가비지 수집 알고리즘을 설계하거나 선택할 때 여러 가지 선택을해야합니다
- Serial versus Parallel
1 |
|
- Concurrent versus Stop-the-world
1 |
|
- Compacting versus Non-compacting versus Copying
1 |
|
Performance Metrics
다음과 같은 가비지 수집기 성능을 평가하기 위해 몇 가지 메트릭이 사용됩니다.
- Throughput — 오랜 시간 동안 고려한 가비지 수집에 소비되지 않은 총 시간의 백분율.
- Garbage collection overhead — 처리량의 역수, 즉 가비지 콜렉션에 소요 된 총 시간의 백분율.
- Pause time — 가비지 수집이 진행되는 동안 응용 프로그램 실행이 중지되는 시간입니다.
- Frequency of collection — 응용 프로그램 실행과 관련하여 수집이 이루어지는 빈도
- Footprint — 힙 크기와 같은 크기 측정 단위입니다.
- Promptness — 객체가 쓰레기가되고 메모리가 사용 가능하게 될 때까지의 시간.
대화 형 응용 프로그램은 일시 중지 시간이 짧을 수 있지만 전반적인 실행 시간은
비대화 형 실시간 응용 프로그램은 가비지 수집 모두에서 작은 상한선을 요구합니다.
휴지기 및 수집기에서 소비 한 시간의 비율을 나타냅니다. 작은 풋 프린트가 메인 일 수 있습니다.
소형 개인용 컴퓨터 또는 임베디드 시스템에서 실행되는 응용 프로그램에 대한 우려.
Generational Collection
generational collection이라는 기술이 사용되면 메모리는 여러 세대로 나누어집니다.
다른 연령대의 개체를 보유하는 풀. 예를 들어, 가장 널리 사용되는 구성에는 두 세대가 있습니다.
하나는 젊은 물건을위한 것이고 다른 하나는 오래된 물건을위한 것입니다.
서로 다른 세대의 가비지 컬렉션을 수행하기 위해 서로 다른 알고리즘을 사용할 수 있습니다. 각 알고리즘은
특정 세대에 대해 일반적으로 관찰되는 특성을 기반으로 최적화됩니다. 세대 별 쓰레기
수집은 약한 세대 가설로 알려진 다음 관찰을 이용한다.
Java 프로그래밍 언어를 포함한 여러 프로그래밍 언어로 작성된 응용 프로그램 :
- 할당 된 대부분의 객체는 오랫동안 참조되지 않고 (라이브로 간주됩니다.) 즉, 젊은 나이에 죽습니다.
- 나이가 많은 개체에서 어린 개체로의 참조가 거의 없습니다.
젊은 세대 컬렉션은 상대적으로 빈번하게 발생하며 효율적이고 빠릅니다. 젊은 세대
공간은 일반적으로 작으며 더 이상 참조되지 않는 많은 객체를 포함 할 가능성이 높습니다.
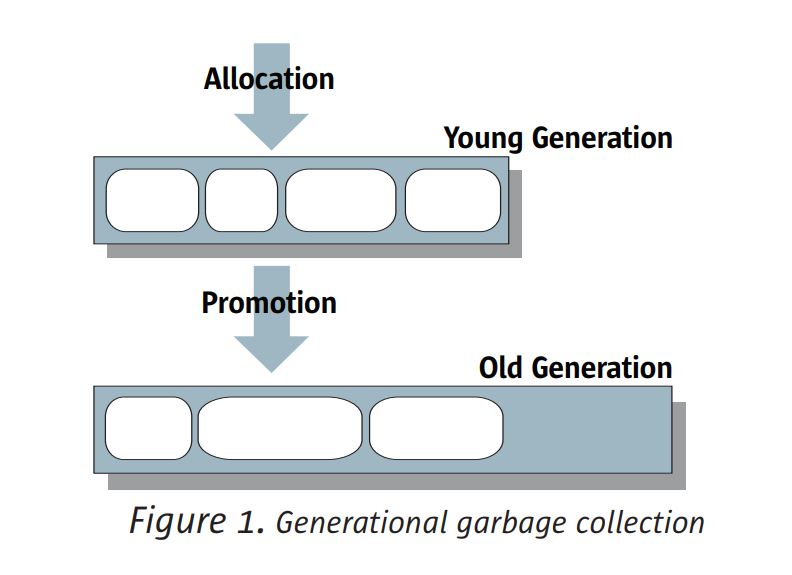
일부 젊은 세대 컬렉션에서 생존하는 객체는 결국 컬렉션으로 승격되거나 종신됩니다.
구세대. 그림 1을 보자.이 세대는 일반적으로 젊은 세대와 그 점유보다 크다.
더 천천히 자랍니다. 결과적으로 구세대 컬렉션은 드물게 발생하지만 오래 걸립니다.
완전한.
젊은 세대를 위해 선택한 가비지 수집 알고리즘은 일반적으로 젊은 세대부터 속도에 프리미엄을 부여합니다.
세대 컬렉션은 빈번합니다. 반면, 구세대는 일반적으로 알고리즘에 의해 관리됩니다
왜냐하면 구세대가 대부분의 힙과 구세대를 차지하기 때문입니다.
알고리즘은 낮은 쓰레기 밀도에서 잘 작동해야합니다.
4 Garbage Collectors in the J2SE 5.0 HotSpot JVM
Java HotSpot 가상 머신에는 J2SE 5.0 업데이트 6부터 4 개의 가비지 콜렉터가 포함되어 있습니다. 모든 콜렉터는
세대. 이 섹션에서는 콜렉션의 세대와 유형을 설명하고 오브젝트가 왜
할당은 종종 빠르고 효율적입니다. 그런 다음 각 콜렉터에 대한 자세한 정보를 제공합니다.
HotSpot Generations
Java HotSpot 가상 시스템의 메모리는 다음 세 세대로 구성됩니다. 젊은 세대, 오래된 세대
세대, 그리고 영구 세대. 대부분의 객체는 처음에는 젊은 세대에 할당됩니다. 오래 된
세대에는 몇 가지 젊은 세대 컬렉션에서 살아남은 객체뿐만 아니라
구세대에 직접 할당 할 수있는 큰 개체. 영구 세대는
JVM은 클래스와 메소드를 설명하는 객체와 같이 가비지 컬렉터를 관리하는 것이 편리하다고 판단하고,
클래스 및 메서드 자체도 포함됩니다
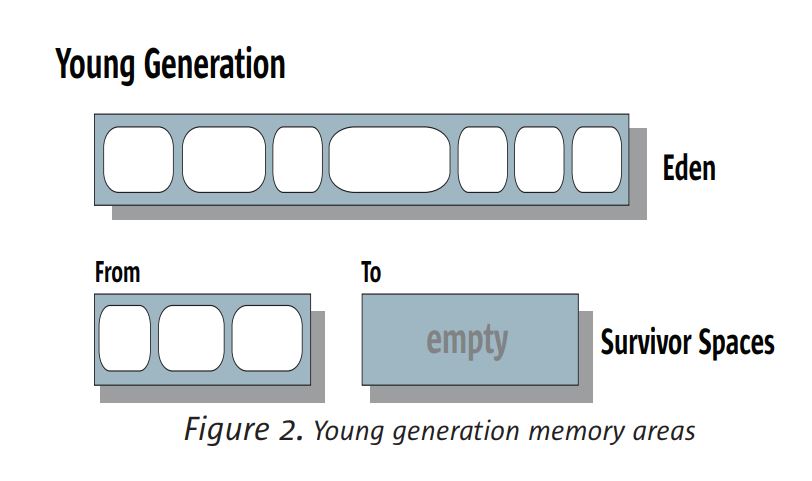
젊은 세대는 그림 2와 같이 에덴 (Eden)이라고 불리는 영역과 2 개의 작은 생존 공간으로 구성됩니다.
대부분의 객체는 처음에 Eden에 할당됩니다. (언급했듯이, 몇 개의 커다란 객체는
오래된 세대.) 생존자 공간은 적어도 한 세대의 젊은 세대 컬렉션에서 살아남은 물체를 보유합니다
따라서 “충분히 오래되었다”고 간주되기 전에 죽을 기회가 더 주어졌습니다.
구세대. 주어진 시간에 생존 공간 중 하나 (그림에서 From라고 표시됨)에는 이러한 객체가 저장되어 있으며,
다른 하나는 비어 있고 다음 수집까지 사용되지 않은 채로 남아 있습니다.
Garbage Collection Types
젊은 세대가 가득 차면 젊은 세대 컬렉션 (때로는 소규모 컬렉션이라고도 함)
그 세대의 일이 수행됩니다. 오래되거나 영구적 인 세대가 가득 차면, 전체로 알려진 것
컬렉션 (때로는 주요 컬렉션이라고 함)이 일반적으로 수행됩니다. 즉, 모든 세대가 수집됩니다.
일반적으로 젊은 세대는 먼저 수집 된 알고리즘을 사용하여 수집됩니다.
왜냐하면 일반적으로 젊은 세대에서 쓰레기를 식별하는 가장 효율적인 알고리즘이기 때문입니다.
그러면 주어진 콜렉터에 대한 구 세대 콜렉션 알고리즘이라고하는 것은
오래되고 영구적 인 세대. 압축이 발생하면 각 세대가 개별적으로 압축됩니다.
때로는 구세대가 너무 커서 전체로부터 승격 될 수있는 모든 물건을 받아 들일 수 없습니다.
어린 세대가 먼저 모아 진다면 젊은 세대는 옛 세대로. 이 경우,
CMS 수집기, 젊은 세대 수집 알고리즘이 실행되지 않습니다. 대신, 구세대 컬렉션
알고리즘은 전체 힙에서 사용됩니다. (CMS 구 세대 알고리즘은 특별한 경우입니다.
젊은 세대를 모으십시오.)
Fast Allocation
아래의 가비지 컬렉터 설명에서 볼 수 있듯이 많은 경우에 큰 연속 블록이 있습니다
객체를 할당 할 수있는 메모리의 양. 이러한 블록의 할당은 간단하며
범프 - 포인터 기술. 즉, 이전에 할당 된 객체의 끝은 항상 추적됩니다. 때
새로운 할당 요청을 만족해야 할 필요가있는 것은 객체가 적합 할지를 검사하는 것이다.
그렇다면 포인터를 업데이트하고 객체를 초기화합니다.
다중 스레드 응용 프로그램의 경우 할당 작업이 다중 스레드 안전해야합니다. 전역 잠금이 사용 된 경우
이를 보장하면 세대에 할당하면 병목 현상이 발생하고 성능이 저하됩니다. 대신,
HotSpot JVM은 Thread-Local Allocation Buffers (TLABs)라는 기술을 채택했습니다. 이것은 향상시킨다.
각 스레드에게 자신의 버퍼를 제공함으로써 멀티 스레딩 할당 처리량 (즉,
세대). 하나의 쓰레드 만이 각 TLAB에 할당 될 수 있기 때문에, 할당은
어떠한 잠금도 요구하지 않고 bump-the-pointer 기술을 활용하여 신속하게 배치 할 수 있습니다. 드문 경우지만,
스레드가 TLAB를 채우고 새 스레드를 가져와야하는 경우 동기화를 사용해야합니다. 몇 가지 기술
TLAB의 사용으로 인한 공간 낭비를 최소화하기 위해 사용됩니다. 예를 들어, TLAB는 할당 자
평균적으로 에덴의 1 % 미만을 낭비합니다. TLAB 사용과 선형 할당의 조합은
bump-the-pointer 기술은 각 할당을 효율적으로 수행 할 수 있으며 약 10 개의 기본 명령어 만 필요합니다.
Serial Collector
시리얼 콜렉터를 사용하면 젊은 세대와 구형 콜렉션 모두가 순차적으로 (단일 CPU를 사용하여), 중단 세계에서
유행. 즉, 수집이 진행되는 동안 응용 프로그램 실행이 중지됩니다.
Young Generation Collection Using the Serial Collector
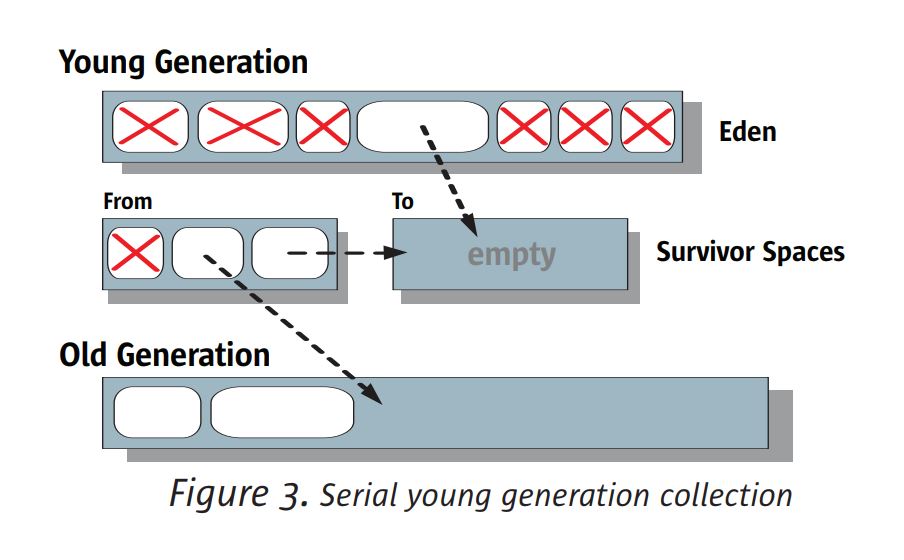
그림 3은 직렬 콜렉터를 사용하는 젊은 세대 콜렉션의 작동을 보여줍니다. 라이브
Eden의 객체는 그림에서 To라는 레이블이 붙은 초기 비어있는 생존 공간으로 복사됩니다 (예외는 제외).
너무 커서 To 공간에 편안하게 맞출 수 없습니다. 이러한 객체는 이전 객체에 직접 복사됩니다.
세대. 점령 된 생존자 공간에있는 살아있는 물체 (From 레이블)는 여전히 비교적 젊다.
다른 생존자 공간에도 복사되는 반면 상대적으로 오래된 개체는 구형 개체로 복사됩니다.
세대. 참고 : To 공간이 가득차면 Eden 또는 From의 라이브 객체가
그들이 살아남은 젊은 세대 컬렉션과는 상관없이 그곳에 복사되어 있습니다. 어떤
Eden에 남아있는 객체 또는 실제 객체를 복사 한 후 From 공간은 정의에 따라 다릅니다.
살아 있고 검사 할 필요가 없습니다. (이 쓰레기 개체는 그림에서 X로 표시되어 있습니다.
사실 수집가는 이러한 객체를 검사하거나 표시하지 않습니다.)
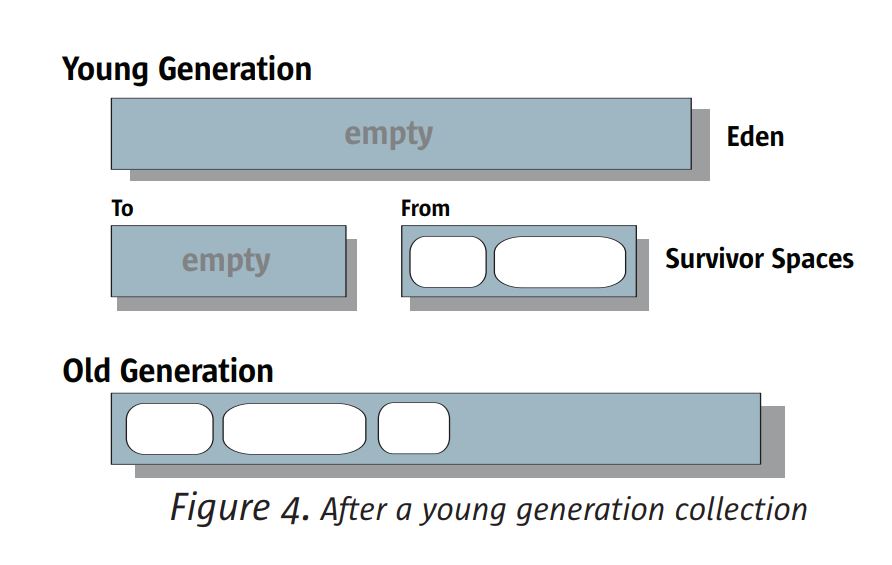
젊은 세대 컬렉션이 완료되면 에덴과 이전에 점령 된 생존자 공간은 모두
비어 있고 오직 이전의 빈 생존자 공간 만이 살아있는 물체를 포함합니다. 이 시점에서, 생존자
공백은 스왑 역할을합니다. 그림 4를 참조하십시오.
Old Generation Collection Using the Serial Collector
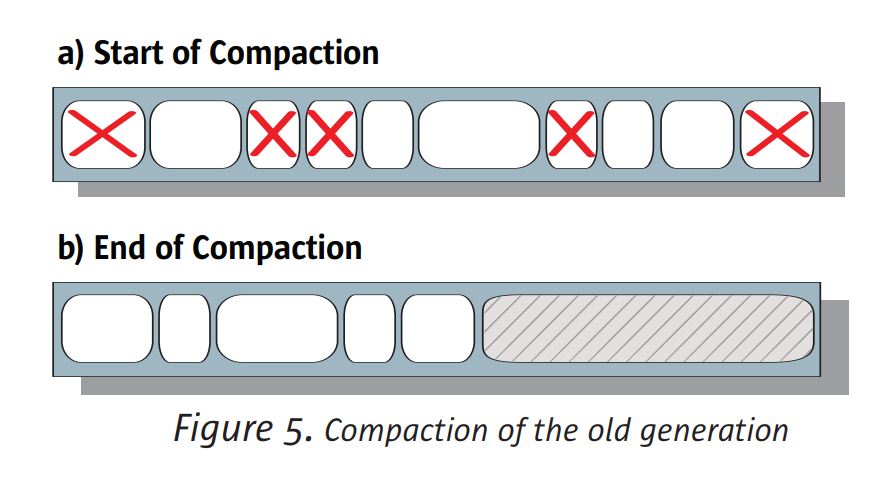
연속 수집기를 사용하면 오래되고 영구적 인 세대가 마크 스윕 콤팩트를 통해 수집됩니다.
수집 알고리즘. 마크 단계에서 수집기는 어떤 객체가 아직 살아 있는지 식별합니다. 스윕
단계가 “쓰레기”를 식별하여 세대를 뒤덮습니다. 콜렉터는 슬라이딩을 수행합니다.
압축 (compaction), 살아있는 물체를 구 세대 공간의 시작 부분으로 밀어 낸다.
영구 생성), 반대쪽 끝의 단일 연속 청크에 여유 공간을 남겨 둡니다. 만나다
그림 5. 압축을 통해 이전 또는 영구 세대에 대한 향후 할당이
빠르고 범프 - 포인터 기법.
When to Use the Serial Collector
직렬 콜렉터는 클라이언트 스타일의 시스템에서 실행되는 대부분의 어플리케이션에 적합한 콜렉터입니다.
낮은 일시 정지 시간을 요구하지 않습니다. 오늘날의 하드웨어에서 직렬 수집기는
64MB 힙과 상대적으로 짧은 최악의 사례로 많은 사소한 애플리케이션을 효율적으로 관리합니다.
전체 수집을 위해 0.5 초 미만의 일시 중지
Serial Collector Selection
J2SE 5.0 릴리스에서는 시리얼 콜렉터가 자동으로 기본 가비지 콜렉터로 선택됩니다.
제 5 절에서 설명 된 것처럼 서버 클래스 머신이 아닌 머신. 다른 머신에서는 직렬
수집기는 -XX : + UseSerialGC 명령 줄 옵션을 사용하여 명시 적으로 요청할 수 있습니다.
Parallel Collector
요즘 많은 Java 응용 프로그램은 많은 실제 메모리와 여러 CPU가있는 시스템에서 실행됩니다. 그만큼
병렬 수집기 (throughput collector라고도 함)는 사용 가능한
CPU가 유휴 상태를 유지하는 대신 가비지 수집 작업 만 수행합니다.
Young Generation Collection Using the Parallel Collector
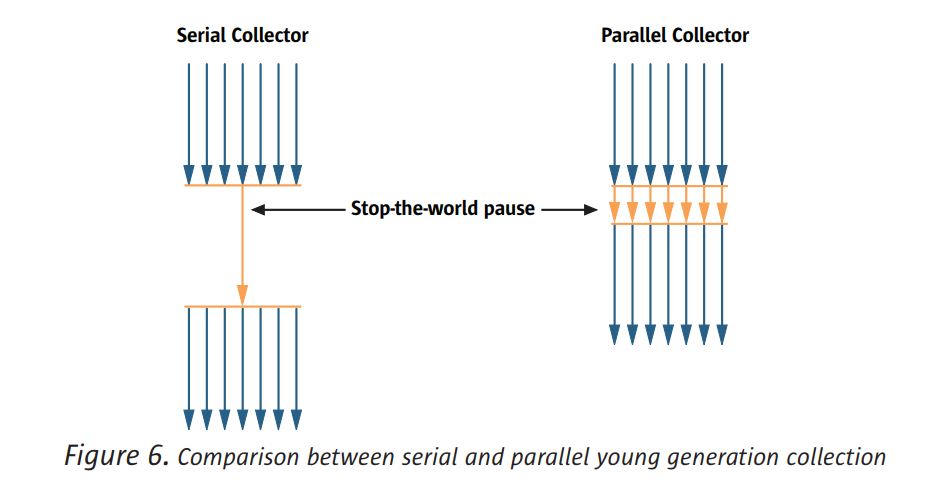
병렬 수집기는 병렬 처리기가 사용하는 젊은 세대 수집 알고리즘의 병렬 버전을 사용합니다.
직렬 수집기. 그것은 여전히 세계와 복사 수집가이지만, 젊은 세대를 수행
많은 CPU를 사용하여 병렬로 수집하면 가비지 콜렉션 오버 헤드가 줄어들어 애플리케이션 처리량이 증가합니다
그림 6은 직렬 수집기와 병렬 젊은 세대를위한 수집가.
Old Generation Collection Using the Parallel Collector
병렬 수집기에 대한 이전 세대 가비지 수집은 동일한 직렬 마크 - 스위프 컴 팩트를 사용하여 수행됩니다.
수집 알고리즘을 직렬 수집기로 사용합니다.
When to Use the Parallel Collector
병렬 수집기의 이점을 누릴 수있는 응용 프로그램은 병렬 수집기 이상을 실행하는 시스템에서 실행되는 응용 프로그램입니다.
하나의 CPU이고 일시적인 시간 제약이 없습니다. 드문 경우지만 오래된 세대이기 때문에
콜렉션은 계속 발생합니다. 병렬 수집기가 종종 적합한 응용 사례
일괄 처리, 대금 청구, 급여 지불, 과학 계산 등을 수행하는 업무를 포함합니다.
병렬 압축 수집기 (다음에 설명 됨)를 병렬로 선택하는 것이 좋습니다
컬렉터, 왜냐하면 전자는 젊은 세대뿐만 아니라 모든 세대의 평행 컬렉션을 수행하기 때문입니다.
세대.
Parallel Collector Selection
J2SE 5.0 릴리스에서는 병렬 수집기가 자동으로 기본 가비지 수집기로 선택됩니다.
서버 클래스 기계 (5 절에서 정의 됨). 다른 컴퓨터에서 병렬 수집기는 명시 적으로
-XX : + UseParallelGC 명령 줄 옵션을 사용하여 요청합니다.
Parallel Compacting Collector
병렬 압축 수집기는 J2SE 5.0 업데이트 6에 도입되었습니다.
수집기는 이전 세대의 가비지 수집을위한 새로운 알고리즘을 사용한다는 것입니다. 참고 : 결국, 병렬
compacting collector가 병렬 수집기를 대체 할 것입니다.
Young Generation Collection Using the Parallel Compacting Collector
평행 집진기를위한 젊은 세대 가비지 수집은
알고리즘을 병렬 수집기를 사용하는 젊은 세대 수집 용 알고리즘으로
Old Generation Collection Using the Parallel Compacting Collector
평행 압축 수집기로, 오래되고 영구적 인 세대는 세계에서 모아집니다.
슬라이딩 압축을 통한 대부분의 병렬 방식. 수집기는 세 단계를 사용합니다. 첫째, 각각
세대는 논리적으로 고정 된 크기의 영역으로 나뉩니다. 마킹 단계에서 라이브 개체의 초기 집합
응용 프로그램 코드에서 직접 접근 할 수있는 가비지 수집 스레드는 가비지 수집 스레드로 나뉘며 그 다음 모두
라이브 오브젝트는 병렬로 표시됩니다. 객체가 실시간으로 식별되면 해당 객체가있는 지역의 데이터가
개체의 크기와 위치에 대한 정보로 업데이트됩니다.
요약 단계는 객체가 아닌 영역에서 작동합니다. 이전 컬렉션의 압축으로 인해
전형적으로 각 세대의 왼쪽 부분의 일부는 밀도가 높고 대부분 생중계가 포함됩니다.
사물. 이러한 고밀도 지역에서 복구 할 수있는 공간의 크기는 비용의 가치가 없습니다.
그들을 압축. 따라서 요약 단계가 수행하는 첫 번째 작업은 지역의 밀도를 검사하는 것입니다.
맨 왼쪽에서부터 복구 할 수있는 공간에 도달 할 때까지 왼쪽 맨 처음부터 시작합니다.
그 지역 오른쪽에있는 지역은 그 지역을 압축하는 데 드는 비용이 든다. 왼쪽 영역
그 점의 조밀 한 접두어로 언급되고, 아무 영역도 그 지역에서 움직이지 않는다. 지역
그 지점의 오른쪽에 모든 죽은 공간을 제거, 압축됩니다. 요약 단계는 다음을 계산합니다.
압축 된 각 영역에 대한 라이브 데이터의 첫 번째 바이트의 새 위치를 저장합니다. 참고 : 요약
단계는 현재 직렬 단계로 구현됩니다. 병렬화는 가능하지만 중요하지는 않습니다.
성능을 마킹 및 압축 단계의 병렬화로 나타냅니다.
압축 단계에서 가비지 콜렉션 스레드는 요약 데이터를 사용하여
채워질 필요가 있고 스레드는 독립적으로 데이터를 영역에 복사 할 수 있습니다. 이것은 힙을 생성합니다.
한쪽 끝은 조밀하게 채워져 있고, 다른 쪽 끝에는 하나의 커다란 빈 블록이 있습니다.
When to Use the Parallel Compacting Collector
병렬 수집기와 마찬가지로 병렬 압축 수집기는 실행되는 응용 프로그램에 유용합니다
둘 이상의 CPU가있는 기계에서. 또한 구 세대 컬렉션의 병렬 작업
일시 정지 시간을 줄이고 병렬 압축 수집기를 병렬보다 더 적합하게 만듭니다
콜렉터는 일시 중지 시간 제한이있는 응용 프로그램에 사용됩니다. 병렬 압축 수집기는
단일 응용 프로그램이없는 대규모 공유 시스템 (예 : SunRays)에서 실행되는 응용 프로그램에 적합해야합니다.
오랜 시간 동안 여러 CPU를 독점해야합니다. 그런 기계에서,
가비지 콜렉션에 사용되는 스레드 수 줄이기 (-XX : ParallelGCThreads = n
명령 행 옵션) 또는 다른 콜렉터를 선택하십시오.
Parallel Compacting Collector Selection
병렬 압축 수집기를 사용하려면 다음을 지정하여 선택해야합니다.
명령 줄 옵션 -XX : + UseParallelOldGC.
Concurrent Mark-Sweep (CMS) Collector
많은 어플리케이션에서 종단 간 처리량은 빠른 응답 시간만큼 중요하지 않습니다. 젊은 세대
컬렉션은 일반적으로 긴 일시 중지를 발생시키지 않습니다. 그러나 오래된 컬렉션은 드물 긴하지만
특히 큰 힙이 포함될 때 긴 일시 중지를 부과하십시오. 이 문제를 해결하기 위해 HotSpot JVM에는
(CMS) 콜렉터라고하는 콜렉터 (저 대기 시간 콜렉터라고도 함)가 있습니다.
Young Generation Collection Using the CMS Collector
CMS 수집기는 병렬 수집기와 동일한 방식으로 새 세대를 수집합니다
Old Generation Collection Using the CMS Collector
CMS 콜렉터를 사용하는 대부분의 구 세대 콜렉션은 다음과 동시에 수행됩니다
응용 프로그램의 실행
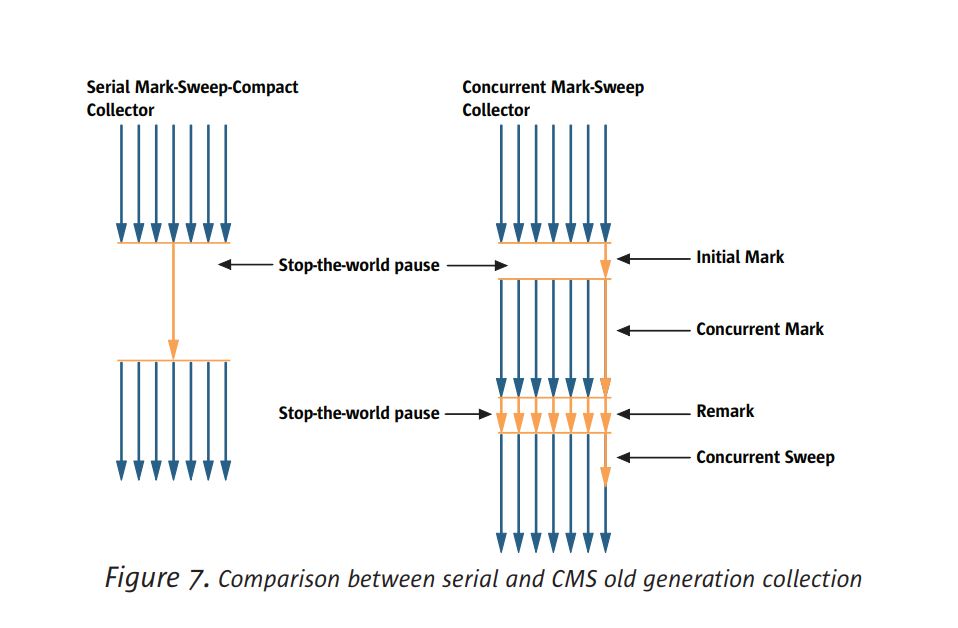
CMS 수집기의 수집주기는 초기 표시라고하는 짧은 일시 중지로 시작됩니다.
응용 프로그램 코드에서 직접 도달 할 수있는 초기 라이브 객체 집합을 식별합니다. 그때,
병행 마킹 단계에서 콜렉터는 전이되는 모든 실시간 객체를 표시합니다
이 집합에서 도달 할 수 있습니다. 응용 프로그램이 실행되고 참조 필드를 업데이트하기 때문에
마킹 단계가 진행 중입니다. 모든 라이브 개체가 마지막 단계에서 표시되도록 보장되어 있지는 않습니다.
동시 마킹 단계. 이를 처리하기 위해 응용 프로그램은 remark라고하는 두 번째 일시 중지를 위해 다시 중지합니다.
동시 마킹 중에 수정 된 객체를 다시 방문하여 마킹을 마무리합니다.
단계. 발언 일시 중지가 초기 표시보다 상당하기 때문에 여러 스레드가 실행됩니다.
병렬로 연결하면 효율이 향상됩니다.
발언 단계가 끝나면 힙의 모든 활성 객체가 표시되도록 보장되므로
후속 동시 스위프 단계는 식별 된 모든 쓰레기를 회수합니다. 그림 7
직렬 마크 - 스윕 - 콤팩트를 사용한 구 세대 컬렉션 간의 차이점
수집기 및 CMS 수집기.
발언 단계에서 객체를 다시 방문하는 것과 같은 일부 작업은 작업량을 증가시킵니다.
컬렉터가해야 할 일은 오버 헤드가 증가하기 때문입니다. 이것은 대부분의 콜렉터에게 일반적인 트레이드 오프입니다.
일시 중지 시간을 줄이려고 시도하십시오.
CMS 수집기는 압축되지 않는 유일한 수집기입니다. 즉, 공간이 확보 된 후
죽은 물체가 점령 한 경우 살아있는 물체를 구세대의 한쪽 끝으로 이동시키지 않습니다. 그림 8을 참조하십시오.
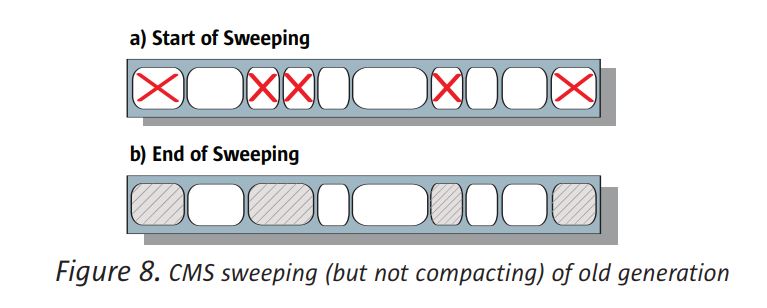
이렇게하면 시간이 절약되지만 여유 공간이 인접하지 않기 때문에 콜렉터는 더 이상 간단한 공간을 사용할 수 없습니다.
포인터는 다음 객체가 할당 될 수있는 다음 자유 위치를 가리킨다. 대신 지금은
무료 목록을 사용해야합니다. 즉, 할당되지 않은 영역을 함께 연결하는 몇 가지 목록을 만듭니다.
메모리를 할당하고 개체를 할당해야 할 때마다 적절한 목록 (
메모리 필요) 개체를 보유 할 수있을만큼 큰 영역을 검색해야합니다. 결과적으로 할당
구세대에 들어가는 것은 단순한 범프 - 포인터 기법을 사용하는 것보다 비용이 많이 든다.
이것은 또한 젊은 세대 컬렉션에 추가 오버 헤드를 부과한다.
세대는 젊은 세대 컬렉션에서 대상을 홍보 할 때 발생합니다.
CMS 수집기의 또 다른 단점은 다른 힙 크기보다 큰 힙 크기에 대한 요구 사항입니다
수집가. 응용 프로그램이 마킹 단계에서 실행되도록 허용되면 응용 프로그램을 계속 실행할 수 있습니다.
메모리를 할당함으로써 잠재적으로 구세대를 계속 성장시킬 수 있습니다. 또한, 비록
수집기가 표시 단계에서 모든 활성 객체를 식별 할 수 있도록 보장합니다. 일부 객체는
그 단계의 쓰레기는 다음 세대 컬렉션까지 회수되지 않습니다. 이러한
개체를 부동 쓰레기(floating garbage)라고합니다.
마지막으로, 단편화는 압축 부족으로 인해 발생할 수 있습니다. 단편화를 다루기 위해 CMS
수집기는 인기있는 객체 크기를 추적하고 미래의 수요를 예측하며 자유 블록을 분할하거나 결합 할 수 있습니다.
수요를 충족하다.
다른 콜렉터와 달리 CMS 콜렉터는 이전 세대 컬렉션이 시작될 때 이전 세대 컬렉션을 시작하지 않습니다.
세대가 가득 차게된다. 대신 컬렉션을 시작하여 컬렉션을 완료 할 수 있도록 시도합니다.
그 일이 있기 전에. 그렇지 않으면 CMS 수집기가 더 많은 시간을 소비하는 세계로 돌아갑니다.
병렬 및 직렬 수집기에서 사용하는 마크 스윕 콤팩트 알고리즘. 이를 피하기 위해 CMS
컬렉터는 이전 수집 시간에 대한 통계 및 이전 수집 시간에 대한 통계를 기반으로 한 번에 시작됩니다.
세대가 점령된다. CMS 수집기는 이전 버전의
세대는 초기 인력이라는 것을 능가합니다. 시작 인원의 가치는
명령 줄 옵션 -XX : CMSInitiatingOccupancyFraction = n으로 설정합니다. 여기서 n은 a입니다.
구세대의 비율. 기본값은 68입니다.
요약하면, 병렬 수집기에 비해 CMS 수집기는 이전 세대의 일시 중지를 줄입니다.
때로는 극적으로 - 젊은 세대가 약간 더 길어 지기도하지만,
처리량 및 여분의 힙 크기 요구 사항이 있습니다.
Incremental Mode
CMS 수집기는 동시 단계가 점진적으로 수행되는 모드에서 사용할 수 있습니다. 이
모드는 주기적으로 동시 실행을 중지하여 긴 동시 발생 단계의 영향을 줄이는 것을 의미합니다.
단계를 수행하여 응용 프로그램에 대한 처리를 다시 수행하십시오. 수집기에 의해 수행 된 작업은 작은
젊은 세대 컬렉션 사이에 예정된 시간대. 이 기능은
동시 콜렉터가 제공하는 낮은 일시 정지 시간을 필요로하는 어플리케이션은 시스템에서 실행됩니다
적은 수의 프로세서 (예 : 1 또는 2)를 사용합니다. 이 모드의 사용법에 대한 자세한 내용은
9 절에서 언급 한 “5.0 Java ™ 가상 시스템으로 가비지 수집 조정”문서
When to Use the CMS Collector
응용 프로그램에서 더 이상 가비지 수집을 일시 중지해야 할 필요가있을 때 CMS 수집기를 사용하십시오.
응용 프로그램이 실행 중일 때 프로세서 자원을 가비지 수집기와 공유하십시오. (그것 때문에
동시성으로 인해 CMS 수집기는 수집주기 동안 CPU주기를 응용 프로그램에서 제거합니다.
일반적으로 수명이 긴 데이터 세트 (대형 구형 세대)가 상대적으로 많은 응용 프로그램과
두 개 이상의 프로세서가있는 컴퓨터에서 실행되는 경우이 수집기의 사용으로 이익을 얻는 경향이 있습니다. 예제
웹 서버가 될 것입니다. 일시 중지 시간이 짧은 모든 애플리케이션에 대해 CMS 수집기를 고려해야합니다.
요구 사항. 또한 오래된 세대의 겸손한 대화 형 응용 프로그램에서도 좋은 결과를 얻을 수 있습니다.
단일 프로세서의 크기.
CMS Collector Selection
CMS 수집기를 사용하려면 명령 줄을 지정하여 명시 적으로 선택해야합니다
옵션 -XX : + UseConcMarkSweepGC. 증분 모드로 실행하려면 해당 옵션을 활성화하십시오.
모드는 -XX : + CMSIncrementalMode 옵션을 통해
5 Ergonomics – Automatic Selections and Behavior Tuning
J2SE 5.0 릴리스에서는 가비지 수집기, 힙 크기 및 HotSpot 가상 시스템 (클라이언트 또는
서버)는 응용 프로그램이있는 플랫폼 및 운영 체제를 기반으로 자동 선택됩니다
달리는. 이러한 자동 선택은 다양한 유형의 응용 프로그램 요구 사항에 더 잘 부합하며
이전 릴리스보다 명령 줄 옵션이 적습니다.
또한 동적 가비지 콜렉션의 새로운 f}이 병렬 가비지 콜렉터에 추가되었습니다. 와
이 접근 방식에서는 사용자가 원하는 동작을 지정하고 가비지 수집기가
요청 된 동작을 얻기위한 힙 영역. 플랫폼 종속적 인 조합
기본 선택 및 원하는 동작을 사용하는 가비지 콜렉션 튜닝을 인체 공학이라고합니다. 그만큼
인체 공학의 목표는 최소한의 명령 행 튜닝으로 JVM에서 우수한 성능을 제공하는 것입니다.
Automatic Selection of Collector, Heap Sizes, and Virtual Machine
서버급 컴퓨터는 다음과 같이 정의됩니다.
- 2 개 이상의 물리적 프로세서
- 2 개 이상의 기가 바이트 실제 메모리
이 서버 클래스 시스템의 정의는 모든 플랫폼에 적용됩니다. 단, 32 비트 플랫폼에서는
버전의 Windows 운영 체제.
서버급 시스템이 아닌 시스템에서 JVM, 가비지 콜렉터 및 힙 크기의 기본값은 다음과 같습니다.
- the client JVM
- the serial garbage collector
- Initial heap size of 4MB
- Maximum heap size of 64MB
서버 클래스 시스템에서 명시 적으로 -client를 지정하지 않으면 JVM은 항상 서버 JVM입니다.
명령 행 옵션을 사용하여 클라이언트 JVM을 요청하십시오. 서버 JVM을 실행하는 서버 클래스 시스템에서 기본값
가비지 수집기는 병렬 수집기입니다. 그렇지 않은 경우 기본값은 직렬 콜렉터입니다
병렬 가비지 컬렉터가있는 JVM (클라이언트 또는 서버)을 실행하는 서버 클래스 시스템에서 기본값
초기 힙 크기와 최대 힙 크기는 다음과 같습니다.
- 물리적 메모리의 1 / 64th의 초기 힙 크기, 최대 1GB. 서버 클래스 컴퓨터는 최소한 2GB의 메모리를 가지며 2 / 64GB는 32MB이기 때문에 최소 초기 힙 크기는 32MB입니다.
- 실제 메모리의 1/4 크기의 최대 힙 크기 (최대 1GB).
그렇지 않은 경우 서버가 아닌 시스템과 동일한 기본 크기가 사용됩니다 (4MB 초기 힙 크기 및 64MB
최대 힙 크기). 디폴트 값은 항상 명령 행 옵션에 의해 대체 될 수 있습니다. 관련 옵션은 다음과 같습니다.
섹션 8에 나와 있습니다.
Behavior-based Parallel Collector Tuning
J2SE 5.0 릴리스에서는 병렬 가비지 수집기에 대해 새로운 튜닝 방법이 추가되었습니다.
가비지 수집과 관련하여 응용 프로그램의 원하는 동작 명령 행 옵션은
최대 일시 중지 시간 및 응용 프로그램 처리량에 대한 목표 측면에서 원하는 동작.
Maximum Pause Time Goal
최대 일시 중지 시간 목표는 명령 줄 옵션으로 지정됩니다.
-XX:MaxGCPauseMillis=n
이것은 병렬 수집기에 대한 힌트로 해석되어 n 밀리 초 이하의 일시 중지 시간은
원하는. 병렬 수집기는 힙 크기 및 기타 가비지 수집 관련 매개 변수를 조정합니다.
가비지 콜렉션 일시 중지를 n 밀리 초보다 짧게 유지하려고 시도합니다. 이러한 조정은
가비지 수집기로 인해 응용 프로그램의 전체 처리량이 감소하고 일부 경우에는
원하는 일시 중지 시간 목표를 달성 할 수 없습니다.
최대 일시 중지 시간 목표는 각 세대에 개별적으로 적용됩니다. 일반적으로 목표가 충족되지 않으면,
목표를 달성하려는 시도에서 세대가 더 작아진다. 최대 일시 중지 시간 목표는 다음에 의해 설정되지 않습니다.
태만.
Throughput Goal
처리량 목표는 가비지 콜렉션을 수행하는 데 소요되는 시간과 소요 시간으로 측정됩니다
가비지 수집 (응용 프로그램 시간이라고 함) 외부. 목표는 명령 행에 의해 지정됩니다.
option
-XX:GCTimeRatio=n
신청 시간에 대한 가비지 수집 시간의 비율은
1 / (1 + n)
예를 들어 -XX : GCTimeRatio = 19는 가비지 수집을위한 총 시간의 5 %를 설정합니다. 그만큼
기본 목표는 1 %입니다 (예 : n = 99). 쓰레기 수거에 소비 된 시간은 모든 세대의 총 시간입니다.
처리량 목표를 달성하지 못하면 세대의 크기가
응용 프로그램이 콜렉션 사이에서 실행할 수있는 시간을 늘리십시오. 더 큰 세대는
채우다.
Footprint Goal
처리량 및 최대 일시 중지 시간 목표를 충족하면 가비지 수집기가 크기를 줄입니다.
목표 중 하나 (항상 처리량 목표)를 충족시킬 수 없을 때까지 힙을 그렇지 않은 목표
만나는 것은 그 다음 해결된다.
Goal Priorities
병렬 가비지 컬렉터는 최대 중지 시간 목표를 먼저 충족 시키려고 시도합니다. 만난 후에 만
처리량 목표를 처리합니까? 마찬가지로 풋 프린트 목표는 처음 두 개 이후에만 고려됩니다.
목표를 달성했다.
6 Recommendations
이전 섹션에서 설명한 인간 공학은 자동 가비지 컬렉터, 가상 시스템 및
응용 프로그램의 큰 비율에 대해 합리적인 힙 크기 선택. 따라서, 초기 권장 사항
가비지 컬렉터를 선택하고 구성하는 것은 아무 것도하지 않는 것입니다! 즉, 특정 사용법을 지정하지 마십시오.
가비지 수집기 등. 시스템이 플랫폼 및 운영 체제를 기반으로 자동 선택을하도록합니다.
귀하의 응용 프로그램이 실행되고 있습니다. 그런 다음 응용 프로그램을 테스트하십시오. 성능이 충분히 만족 스럽다면
높은 처리량과 충분히 낮은 일시 중지 시간이 완료되었습니다. 문제를 해결하거나 수정할 필요가 없습니다.
가비지 컬렉터 옵션.
반면에 응용 프로그램에서 가비지 수집과 관련된 성능 문제가있는 것으로 보인다면
가장 먼저 할 수있는 일은 기본적으로 선택된 가비지 컬렉터가 적절한 지 생각하는 것입니다.
귀하의 응용 프로그램 및 플랫폼 특성을 고려하십시오. 그렇지 않은 경우 명시 적으로 콜렉터를 선택하십시오.
적절하며 성능이 수용 가능한지 여부를 확인하십시오.
7 절에서 설명 된 것과 같은 도구를 사용하여 성능을 측정하고 분석 할 수 있습니다.
결과에서 힙 크기 또는 가비지 수집을 제어하는 옵션 수정 옵션을 고려할 수 있습니다
행동. 가장 일반적으로 지정된 옵션 중 일부는 섹션 8에 나와 있습니다. 참고 : 최상의 접근 방식
퍼포먼스 튜닝은 먼저 측정하고 나서 튜닝하는 것입니다. 코드가 수행되는 방식과 관련된 테스트를 사용하여 측정
실제로 사용됩니다. 또한 응용 프로그램 데이터 세트, 하드웨어 등등 과부하가 걸리기 때문에 과도하게 최적화해야합니다.
가비지 컬렉터 구현! - 시간이 지나면 바뀔 수도 있습니다.
이 섹션에서는 가비지 수집기 선택 및 힙 크기 지정에 대한 정보를 제공합니다. 그런 다음
병렬 쓰레기 수거자를 조정하기위한 제안 사항 및 수행 할 작업과 관련된 조언
OutOfMemoryErrors.
When to Select a Different Garbage Collector
4 절에서는 각 수집기에 대해 해당 수집기의 사용을 권장하는 상황을 설명합니다. 섹션 5
직렬 또는 병렬 수집기가 기본적으로 자동 선택되는 플랫폼을 설명합니다.
응용 프로그램 또는 환경 특성이 기본값과 다른 수집기 인 경우
다음 명령 행 옵션 중 하나를 통해 콜렉터에게 명시 적으로 요청하십시오.
–XX:+UseSerialGC
–XX:+UseParallelGC
–XX:+UseParallelOldGC
–XX:+UseConcMarkSweepGC
Heap Sizing
섹션 5는 초기 힙 크기와 기본 힙 크기를 알려줍니다. 그 크기는 많은 사람들에게 좋을 수 있습니다.
그러나 성능 문제 (7 절 참조) 또는 OutOfMemoryError
(이 섹션의 뒷부분에서 설명 함)은 특정 세대 또는 전체 힙 크기에 문제가 있음을 나타내며,
섹션 8에 지정된 명령 행 옵션을 통해 크기를 수정할 수 있습니다. 예를 들어, 기본 최대 값
비 서버급 시스템에서 64MB의 힙 크기는 종종 너무 작기 때문에 -Xmx를 사용하여 더 큰 크기를 지정할 수 있습니다.
선택권. 긴 일시 중지 시간에 문제가없는 한 힙에 가능한 한 많은 메모리를 부여하십시오.
처리량은 사용 가능한 메모리 양에 비례합니다. 충분한 사용 가능한 메모리가 가장 많습니다.
15 권장 사항 Sun Microsystems, Inc.
가비지 수집 성능에 영향을 미치는 중요한 요소.
총 힙에 제공 할 수있는 총 메모리 양을 결정한 후에는
다른 세대의 크기를 조정합니다. 가비지 수집에 영향을 미치는 두 번째로 영향력있는 요소
성능은 젊은 세대에게 할당 된 힙의 비율입니다. 문제가없는 한
지나치게 오래된 세대 컬렉션 또는 일시 중지 시간은 젊은 세대에게 충분한 메모리를 제공합니다. 하나,
직렬 콜렉터를 사용할 때는 젊은 세대에 총 힙 크기의 절반 이상을 부여하지 마십시오.
병렬 가비지 수집기 중 하나를 사용하는 경우, 가비지 수집기 대신 원하는 동작을 지정하는 것이 바람직합니다.
정확한 힙 크기 값. 수집기가 자동으로 동적으로 힙 크기를 수정하여
그 행동은 다음에 설명됩니다.
Tuning Strategy for the Parallel Collector
선택한 가비지 수집기 (자동 또는 명시 적으로)가 병렬 수집기 또는 병렬 압축 인 경우
그런 다음 처리량 목표 (섹션 5 참조)를 지정하여 애플리케이션에 충분합니다.
기본값보다 큰 힙이 필요하다는 것을 알지 못하는 경우 힙의 최대 값을 선택하지 마십시오.
최대 힙 크기. 힙은 선택한 처리량 목표를 지원하는 크기로 증가하거나 축소됩니다.
초기화 중 및 응용 프로그램 동작이 변경되는 동안 힙 크기의 일부 진동은
기대된다.
힙이 최대 값까지 증가하면 대부분의 경우 처리량 목표를 충족시킬 수 없습니다.
그 최대 크기. 최대 크기를 플랫폼의 총 실제 메모리에 가까운 값으로 설정하십시오.
하지만 그것은 응용 프로그램의 교환을 일으키지 않습니다. 응용 프로그램을 다시 실행하십시오. 처리량 목표가
여전히 충족되지 않으면 응용 프로그램 시간의 목표가 플랫폼의 사용 가능한 메모리에 비해 너무 높습니다.
처리량 목표를 달성 할 수 있지만 너무 긴 일시 중지가있는 경우 최대 일시 중지 시간 목표를 선택하십시오.
최대 일시 중지 시간 목표를 선택하면 처리량 목표를 달성하지 못할 수 있으므로 값을 선택하십시오.
이는 응용 프로그램에 대한 적절한 절충안입니다.
가비지 컬렉터가 경쟁 목표를 만족 시키려고 시도 할 때 힙의 크기는 진동합니다.
응용 프로그램이 안정된 상태에 도달했습니다. 처리량 목표를 달성하라는 압력 (큰
힙)은 최대 휴지 시간 및 최소 풋 프린트에 대한 목표와 경쟁합니다 (둘 다
작은 힙).
What to Do about OutOfMemoryError
많은 개발자가 해결해야하는 한 가지 일반적인 문제는 다음과 같이 끝나는 응용 프로그램의 문제입니다.
java.lang.OutOfMemoryError. 이 오류는 할당 할 공간이 충분하지 않을 때 발생합니다.
목적. 즉, 가비지 수집은 새로운 객체를 수용 할 수있는 추가 공간을 만들 수 없으며
힙을 더 이상 확장 할 수 없습니다. OutOfMemoryError는 반드시 메모리 누수를 의미하지는 않습니다. 그만큼
문제는 단순히 구성 문제 일 수 있습니다. 예를 들어 지정된 힙 크기 (또는 그렇지 않은 경우 기본 크기)
지정된) 응용 프로그램에 충분하지 않습니다.
OutOfMemoryError 진단의 첫 번째 단계는 전체 오류 메시지를 검사하는 것입니다. 예외적으로
추가 정보는 “java.lang.OutOfMemoryError”다음에 제공됩니다. 여기에 몇 가지 공통점이있다.
그 추가 정보가 무엇인지, 그것이 무엇을 의미하는지, 그리고 그것에 대해 어떻게해야하는지에 대한 예 :
- Java heap space
1 |
|
- PermGen space
1 |
|
- Requested array size exceeds VM limit
1 |
|
섹션 7에 설명 된 도구 중 일부는 OutOfMemoryError 문제를 진단하는 데 사용할 수 있습니다. 소량의
이 작업을위한 가장 유용한 도구는 HAT (힙 분석 도구), jconsole 관리 도구 및
jmap 도구를 -histo 옵션과 함께 사용하십시오.
7 Tools to Evaluate Garbage Collection Performance
다양한 진단 및 모니터링 도구를 사용하여 가비지 수집 성능을 평가할 수 있습니다. 이 구역
그 중 일부에 대한 간략한 개요를 제공합니다. 자세한 내용은의 “도구 및 문제 해결”링크를 참조하십시오.
섹션 9.
–XX:+PrintGCDetails Command Line Option
가비지 콜렉션에 대한 초기 정보를 얻는 가장 쉬운 방법 중 하나는 명령 행을 지정하는 것입니다
옵션 -XX : + PrintGCDetails. 모든 콜렉션에 대해 이것은 결과와 같은 정보를 출력합니다.
다양한 세대의 가비지 콜렉션 전후의 라이브 오브젝트 크기,
각 세대, 그리고 수집에 소요 된 시간.
–XX:+PrintGCTimeStamps Command Line Option
이 명령은 각 콜렉션의 시작 부분에 타임 스탬프를 출력하고,
명령 줄 옵션 -XX : + PrintGCDetails가 사용됩니다. 타임 스탬프는 쓰레기 상관 관계를 도울 수 있습니다.
다른 기록 된 이벤트와 함께 수집 로그.
jmap
jmap은 Solaris ™ 운영 환경 및 Linux (Windows는 제외)에 포함 된 명령 줄 유틸리티입니다.
Java Development Kit (JDK ™)의 릴리스. 실행중인 JVM 또는 코어 파일에 대한 메모리 관련 통계를 인쇄합니다. 그 경우
명령 줄 옵션없이 사용되면로드 된 공유 객체 목록을 인쇄합니다.
Solaris pmap 유틸리티 출력. 보다 자세한 정보는 -heap, -histo 또는 -permstat 옵션을 사용할 수 있습니다.
-heap 옵션은 가비지 콜렉터의 이름을 포함하는 정보를 얻는 데 사용됩니다.
알고리즘 별 세부 정보 (예 : 병렬 가비지 수집에 사용되는 스레드 수), 힙
구성 정보 및 힙 사용 요약
-histo 옵션을 사용하여 클래스 힙의 히스토그램을 얻을 수 있습니다. 각 클래스에 대해 숫자를 인쇄합니다.
힙에있는 인스턴스 수, 해당 개체에서 소비 한 총 메모리 크기 (바이트) 및
정규화 된 클래스 이름. 히스토그램은 힙 사용 방법을 이해할 때 유용합니다.
영구 생성의 크기를 구성하는 것은 동적으로 생성하는 응용 프로그램에 중요 할 수 있습니다
많은 수의 클래스 (예 : Java Server Pages ™ 및 웹 컨테이너)를로드합니다. 응용 프로그램이로드되는 경우
“너무 많은”클래스가 있으면 OutOfMemoryError가 발생합니다. jmap 명령에 대한 -permstat 옵션은 다음을 수행 할 수 있습니다.
영구 생성에서 개체에 대한 통계를 가져 오는 데 사용됩니다.
jstat
jstat 유틸리티는 HotSpot JVM에 내장 된 도구를 사용하여 성능 정보를 제공합니다
실행중인 응용 프로그램의 자원 소비. 이 도구는 성능 문제를 진단 할 때 사용할 수 있습니다.
특히 힙 크기 조정 및 가비지 수집과 관련된 문제가 있습니다. 많은 옵션 중 일부는 인쇄 할 수 있습니다.
쓰레기 수거 행동 및 다양한 세대의 수용력과 사용량에 관한 통계.
HPROF: Heap Profiler
HPROF는 JDK 5.0과 함께 제공되는 간단한 프로파일 러 에이전트입니다. 동적으로 링크 된 라이브러리로,
JVM (Java Virtual Machine Tools Interface)을 사용하는 JVM 프로파일 링 정보를 파일에 기록하거나
ASCII 또는 2 진 형식의 소켓에 연결하십시오. 이 정보는 프로파일 러 프런트 엔드 도구로 추가 처리 할 수 있습니다.
HPROF는 CPU 사용량, 힙 할당 통계 및 모니터 경합 프로파일을 표시 할 수 있습니다. 에서
또한 완전한 힙 덤프를 출력하고 Java의 모든 모니터 및 스레드 상태를보고 할 수 있습니다
가상 기기. HPROF는 성능, 잠금 경합, 메모리 누수 및 기타 문제를 분석 할 때 유용합니다.
HPROF 문서에 대한 링크는 9 절을 참조하십시오.
HAT: Heap Analysis Tool
힙 분석 도구 (HAT)는 의도하지 않은 개체 보존을 디버그하는 데 유용합니다. 이 용어는 객체를 설명하는 데 사용됩니다.
더 이상 필요하지 않지만 살아있는 객체로부터의 어떤 경로를 통한 참조로 인해 유지됩니다. HAT는
HPROF를 사용하여 생성 된 힙 (heap) 스냅 샷의 객체 토폴로지를 찾아 볼 수있는 편리한 방법입니다. 도구
“루트 집합에서이 객체로의 모든 참조 경로 표시”를 포함한 많은 쿼리를 허용합니다.
HAT 문서에 대한 링크는 9 페이지를 참조하십시오.
8 Key Options Related to Garbage Collection
가비지 콜렉터를 선택하거나 힙이나 생성 크기를 지정하거나,
가비지 수집 동작을 수정하고 가비지 수집 통계를 얻을 수 있습니다. 이 섹션에서는
가장 일반적으로 사용되는 옵션. 다양한 옵션에 대한 자세한 목록과 자세한 정보는
주 : 지정하는 숫자는 메가 바이트의 경우 “m”또는 “M”으로 끝나며, 메가 바이트의 경우 “k”또는 “K”로 끝날 수 있습니다.
킬로바이트, “g”또는 “G”(기가 바이트).
Garbage Collector Selection
| Option | Garbage Collector Selected |
|---|---|
| –XX:+UseSerialGC | Serial |
| –XX:+UseParallelGC | Parallel |
| –XX:+UseParallelOldGC | Parallel compacting |
| –XX:+UseConcMarkSweepGC | Concurrent mark–sweep (CMS) |
Garbage Collector Statistics
| Option | Description |
|---|---|
| –XX:+PrintGC | Outputs basic information at every garbage collection. |
| –XX:+PrintGCDetails | Outputs more detailed information at every garbage collection. |
| –XX:+PrintGCTimeStamps | Outputs a time stamp at the start of each garbage collection event. Used with –XX:+PrintGC or –XX:+PrintGCDetails to show when each garbage collection begins. |
Heap and Generation Sizes
| Option | Default | Description |
|---|---|---|
| –Xmsn | Initial heap size of 1/64th of the physical memory, up to 1GB. (Note that the minimum initial heap size is 32MB, since a server-class machine is defined to have at least 2GB of memory and 1/64th of 2GB is 32MB.) | Initial size, in bytes, of the heap. |
| –Xmxn | Maximum heap size of 1/4th of the physical memory, up to 1GB. | Maximum size, in bytes, of the heap. |
| –XX:MinHeapFreeRatio=minimum and –XX:MaxHeapFreeRatio=maximum | 40 (min) 70 (max) | Target range for the proportion of free space to total heap size. These are applied per generation. For example, if minimum is 30 and the percent of free space in a generation falls below 30%, the size of the generation is expanded so as to have 30% of the space free. Similarly, if maximum is 60 and the percent of free space exceeds 60%, the size of the generation is shrunk so as to have only 60% of the space free. |
| –XX:NewSize=n | Platform–dependent | Default initial size of the new (young) generation, in bytes. |
| –XX:NewRatio=n | 2 on client JVM, 8 on server JVM | Ratio between the young and old generations. For example, if n is 3, then the ratio is 1:3 and the combined size of Eden and the survivor spaces is one fourth of the total size of the young and old generations. |
| –XX:SurvivorRatio=n | 32 | Ratio between each survivor space and Eden. For example, if n is 7, each survivor space is one–ninth of the young generation (not one–eighth, because there are two survivor spaces). |
| –XX:MaxPermSize=n | Platform–dependent | Maximum size of the permanent generation. |
Options for the Parallel and Parallel Compacting Collectors
| Option | Default | Description |
|---|---|---|
| –XX:ParallelGCThreads=n | The number of CPUs | Number of garbage collector threads. |
| –XX:MaxGCPauseMillis=n | No default | Indicates to the collector that pause times of n milliseconds or less are desired. |
| –XX:GCTimeRatio=n | 99 | Number that sets a goal that 1/(1+n) of the total time be spent on garbage collection. |
Options for the CMS Collector
| Option | Default | Description |
|---|---|---|
| –XX:+CMSIncrementalMode | Disabled | Enables a mode in which the concurrent phases are done incrementally, periodically stopping the concurrent phase to yield back the processor to the application. |
| –XX:+CMSIncrementalPacing | Disabled | Enables automatic control of the amount of work the CMS collector is allowed to do before giving up the processor, based on application behavior. |
| –XX:ParallelGCThreads=n | The number of CPUs | Number of garbage collector threads for the parallel young generation collections and for the parallel parts of the old generation collections. |